

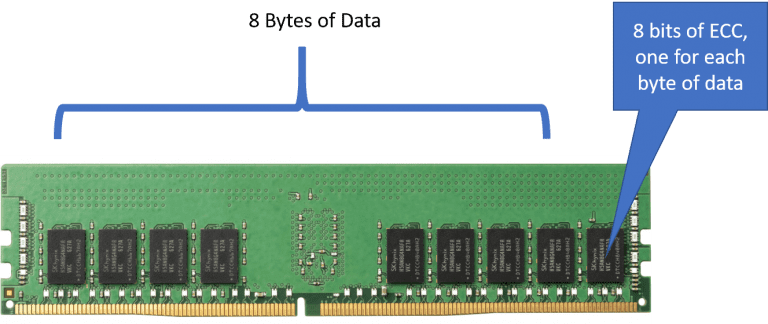
Is it the DIMM or the System?
For DDR4 DIMMs and SODIMMs (that support ECC) the ECC (Error Correcting Code) is calculated by the Memory Controller for each byte on a write. A single bit per byte is provided as part of the calculation and is stored in a different device than the byte its protecting is stored in. However, there is no checking of the write data once it reaches the DRAM. The ECC is really only used to protect the data on the Read. Once the data is read back, the Memory Controller checks the ECC and if incorrect tries to do some kind of recovery. That recovery is system dependent and not specified by the JEDEC spec. In fact, the ECC calculations and algorithms are also not specified and many system vendors do not release their ECC algorithms. If it is a single bit error it will do the correction and write back the corrected data to the DRAM. Single bit errors are also called ‘Soft Errors’. If it detects a double bit error it cannot do any correction as the ECC algorithm is mathematically limited and can only do Single Error Detection and Correction but only Double bit error Detection. You may have seen the acronym SECDED and this is where it comes from, Single Error Correction, Double Error Detection. Double bit errors are sometimes referred to as ‘Hard Errors’ and they will usually cause a machine check and a system crash. System log files should show all of the soft errors and the address that the error occurred on. In addition, it should indicate all hard errors and what read address generated the double bit error.
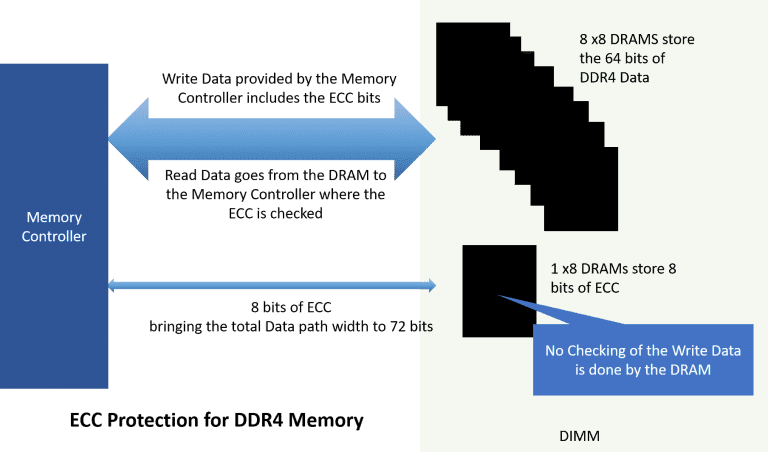
The data originates with the memory controller and passes across the memory channel, and into the DRAM. If the memory channel suffers from crosstalk, power fluctuations or other Signal Integrity issues the data may not be good when it reaches the DRAM and since there is no checking at the DRAM we do not know if it actually arrived correctly.
Next the Write Data is stored in the DRAM and sits, for maybe days. It could get corrupted while it sits in the DRAM (many ways this can happen!). When it eventually gets read by the Memory Controller the ECC is calculated to see if a single or double bit error can be detected. If there is more than a single or double bit error it goes undetected. Imagine the havoc that would wreck on a critical application! Now the vast majority of the time, the data is good, but in the case of an error, the error handling is not specified anywhere. Many people do not understand that the JEDEC spec is a DRAM spec not a system or memory controller specification. To complicate matters the memory controller does not signal onto the DDR4 bus that it has detected an error. So we cannot trigger a logic analyzer or a scope on the offending Read transaction.
So how do we figure out who to blame the errors on? Because the DDR4 (and DDR3 before it) architecture is poor with regards to timely error detection and recovery we have to take a pragmatic approach. We must validate the channel by looking at the signal integrity under heavy and light loads. We must check the memory controller for protocol violations. Which might be due to the BIOS incorrectly setting the timing parameters. We need to look at the signal integrity of the read data to see if the DIMM has problems. We need to check the SPD to see if the correct parameters are being programed into the DRAM by the Memory Controller. We also need to look at the applications that are causing the system to fail most often to see if traffic patterns could indicate a ‘Row Hammer’ event. All of this and MORE, much more, validation and test should occur before the platform ever sees the light of day (and a Validation Report generated). If failures are occurring in the field a Memory Channel Audit can be performed.
So to answer the question of ‘who get’s the blame’. We look for all the evidence that most likely contributes to problems and we compile a list of things that can be changed and the system re-tested to see if that reduces the ECC errors. So far our team is batting a 1000 with documented proof of problems and suggested fixes that led to positive results. Got DDR problems? Contact us.